Historical Dictionary of Switzerland Out of the Box
The Historical Dictionary of Switzerland (HDS) is an academic reference work which documents the most important topics and objects of Swiss history from prehistory up to the present.
The HDS digital edition comprises about 36.000 articles organized in 4 main headword groups:
- Biographies,
- Families,
- Geographical entities and
- Thematical contributions.
Beyond the encyclopaedic description of entities/concepts, each article contains references to primary and secondary sources which supported authors when writing articles.
Data
We have the following data:
* metadata information about HDS articles Historical Dictionary of Switzerland comprising:
- bibliographic references of HDS articles
- article titles
* Le Temps digital archive for the year 1914
Goals
Our projects revolve around linking the HDS to external data and aim at:
- Entity linking towards HDS
The objective is to link named entity mentions discovered in historical Swiss newspapers to their correspondant HDS articles.
- Exploring reference citation of HDS articles
The objective is to reconcile HDS bibliographic data contained in articles with SwissBib.
Named Entity Recognition
We used web-services to annotate text with named entities:
- Dandelion
- Alchemy
- OpenCalais

Named entity mentions (persons and places) are matched against entity labels of HDS entries and directly linked when only one HDS entry exists.
Further developments would includes:
- handling name variants, e.g. 'W.A. Mozart' or 'Mozart' should match 'Wolfgang Amadeus Mozart' .
- real disambiguation by comparing the newspaper article context with the HDS article context (a first simple similarity could be tf-idf based)
- working with a more refined NER output which comprises information about name components (first, middle,last names)
Some statistics
In the 23.622 articles of the year 1914 in «Le Temps digital archive» we linked 90.603 entities pointing to 1.417 articles of the «Historical Dictionary of Switzerland».

Web Interface
We developed a simple web interface for searching in the corpus and displaying the texts with the links.
It consists of 3 views:
1. Home
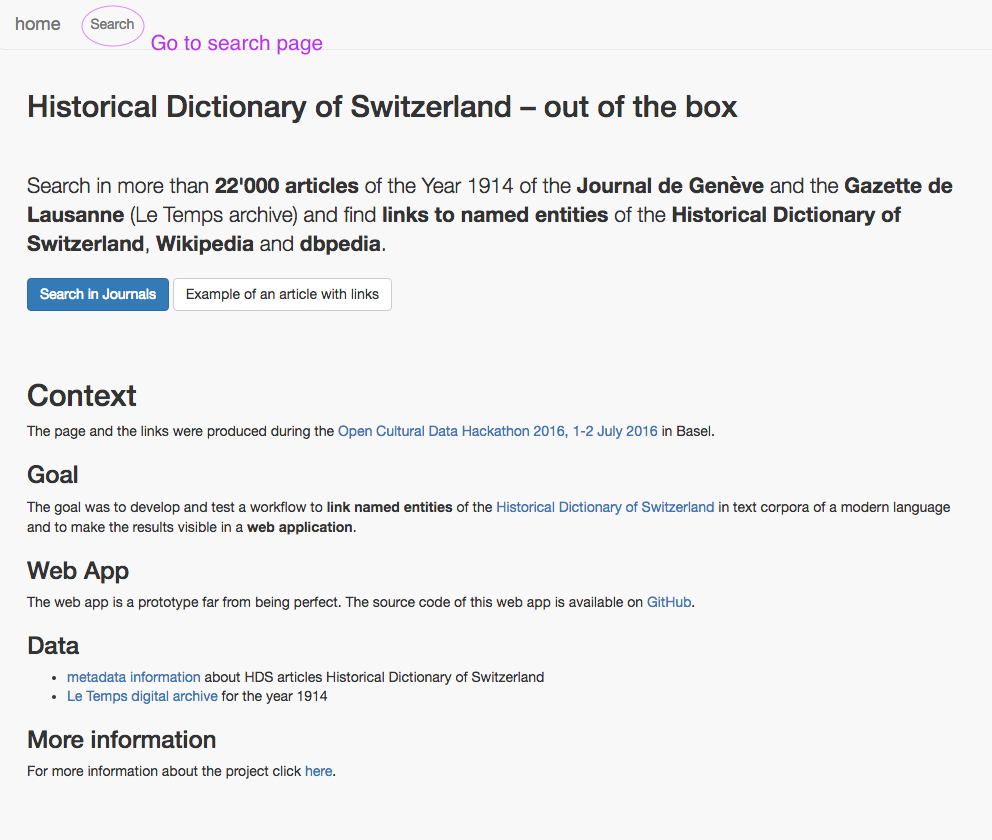
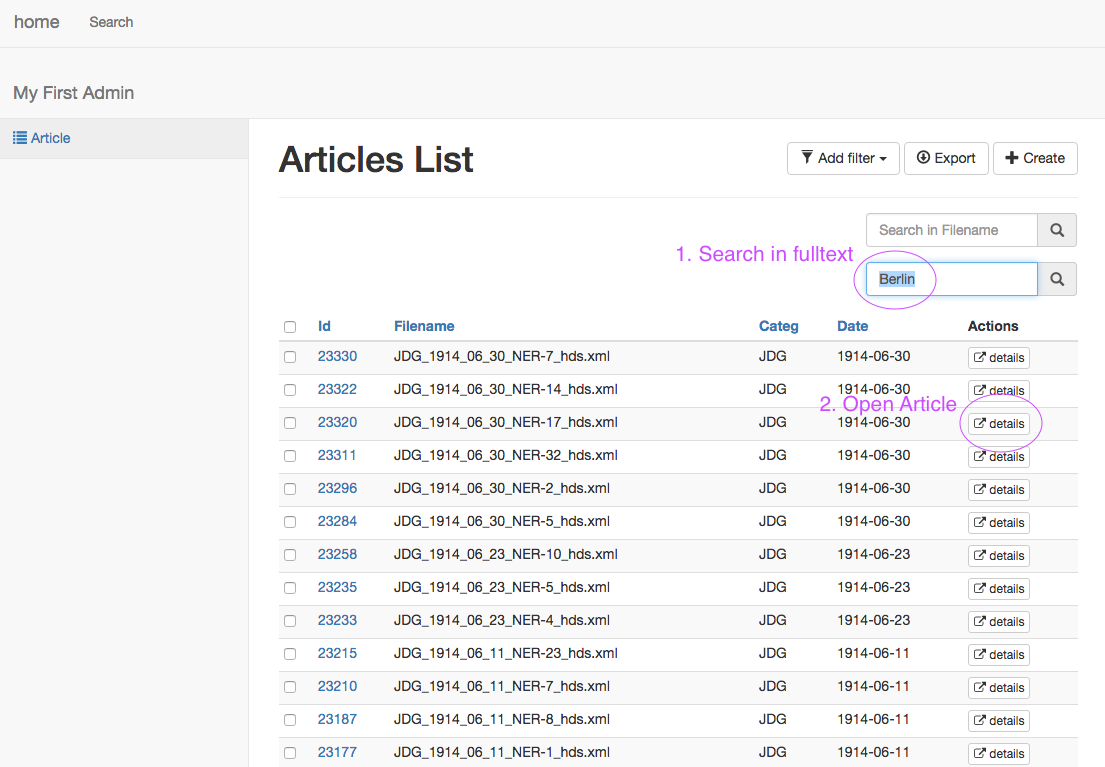
2. Search
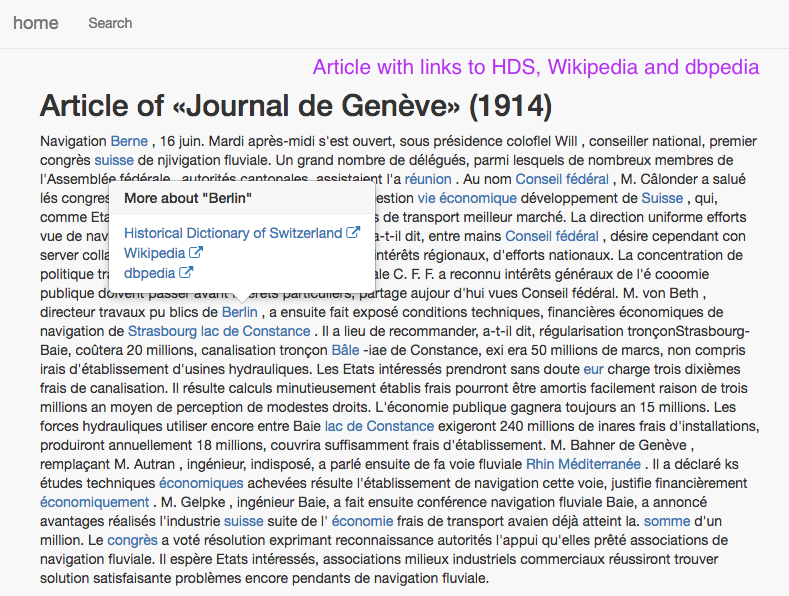
3. Article with links to HDS, Wikipedia and dbpedia
Further works
Further works would include:
- evaluate and improve method.
- apply the method to the Historical Dictionary of Switzerland itself for internal linking.
Bibliographic enrichment
We work on the list of references in all articles of the HDS, with three goals:
- Finding all the sources which are cited in the HDS (several sources are cited multiple times) ;
- Link all the sources with the SwissBib catalog, if possible ;
- Interactively explore the citation network of the HDS.
The dataset comes from the HDS metadata. It contains lists of references in every HDS article:

Result of source disambiguation and look-up into SwissBib:
Bibliographic coupling network of the HDS articles (giant component). In Bibliographic coupling two articles are connected if they cite the same source at least once. Biographies (white), Places (green), Families (blue) and Topics (red):
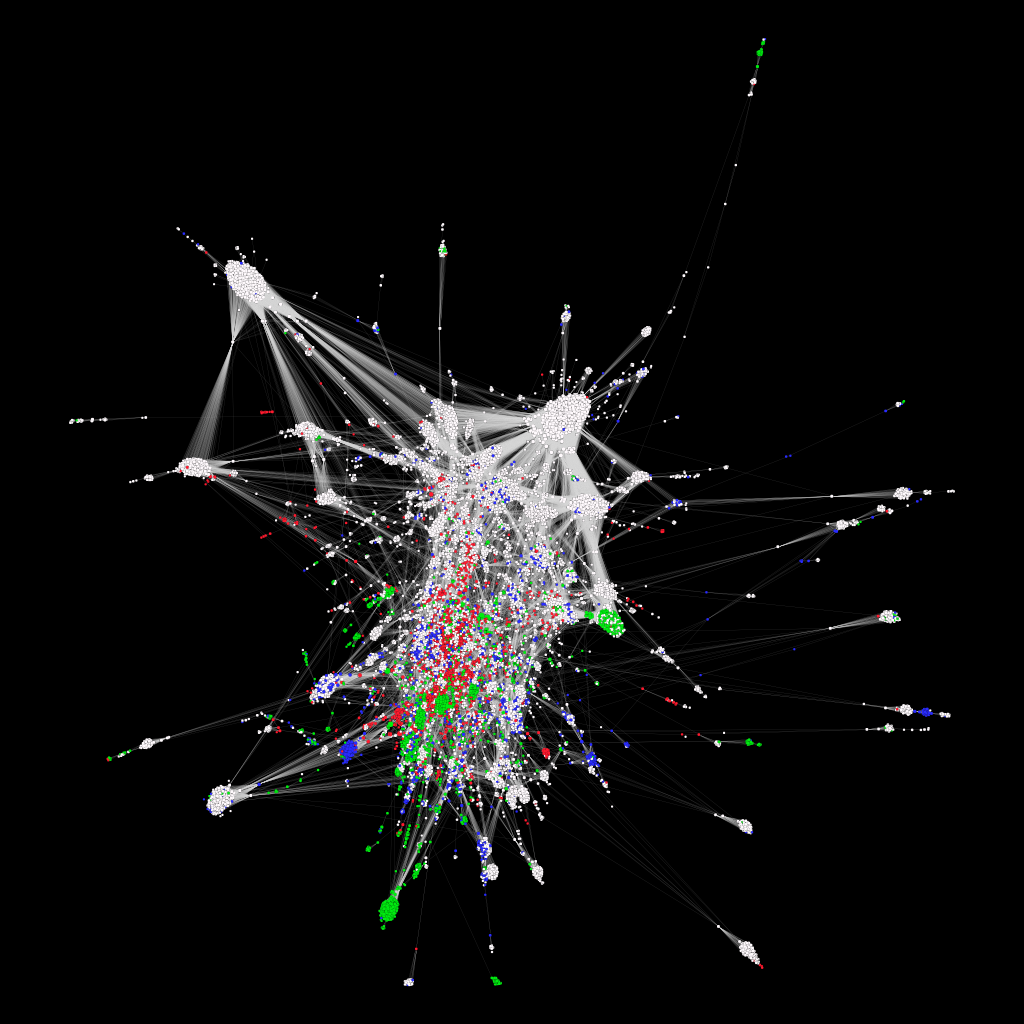
Ci-citation network of the HDS sources (giant component of degree > 15). In co-citation networks, two sources are connected if they are cited by one or more articles together. Publications (white), Works of the subject of an article (green), Archival sources (cyan) and Critical editions (grey):

Exploring bibliographic enrichment with OpenRefine
Bibliographic data in the HDS citations is unfortunately not structured. There is no logical separation between work title, publication year, page numbers, etc. other than typographical convention. Furthermore, many citations contain abbreviations. Using OpenRefine to explore the dataset, multiple approaches were attempted to query the swissbib SRU API using unstructured citation data.
Examples of unstructured data issues
- L'oro bruno - Cioccolato e cioccolatieri delle terre ticinesi, Ausstellungskat. Lottigna, 2007 - Elements of the citation are sometimes divided by commas (,) but there is no fixed rule. In this case, the first comma separates the title from an object type. Another comma separates the place of publication with the publication year.
- A. Niederer, «Vergleichende Bemerkungen zur ethnolog. und zur volkskundl. Arbeitsweise», in Beitr. zur E. der Schweiz 4, 1980, 1-25 - This citation mentions an article within a collection, the commas separate publication year and page numbers.
- La visite des églises du diocèse de L. en 1453, hg. von A. Wildermann et al., 1993 - The subject of the dictionary entry is often abbreviated in the related citations. In this example, “L.” stands for Lausanne, because the citation comes from the dictionary entry for Lausanne.
- Stat. Jb. des Kt. L., 2002- - In this example, “L.” stands for Luzern. The other abbreviations are standard and can be resolved using the dictionary's list of abbreviations.
OpenRefine workflow
After several attempts, it was established that combining several keywords from the reference title with the authors (without initials) produced the best results for querying swissbib. The following GREL expression can be applied to the OpenRefine column (using Edit column → Add column based on this column) that contains the contents of the <NOTICE><PUB> field to create a search string:
join(with(value.split(" "),a,forEach(a,v,v.chomp(",").match(/([a-zA-Z\u00C0-\u017F-']{4,}|\d{4})/)[0]))," ")+" "+forNonBlank(cells["NOTICE - AUT"],v,v.value.match(/(.* |)(\w{2,})/)[1]," ")
Note that the above expression combines the <PUB> column (accessed through value) and the <AUT> column (containing the author's name). Replace the reference to the authors' column accordingly if it has a different name in your data file.
Swissbib queries can return Dublin Core, MARC XML or MARC in JSON format. Dublin core is the easiest to manipulate, but unfortunately it does not contain the entirety of the returned record. To access the full record, it is necessary to use either MARC XML or MARC JSON.
To query swissbib and return Dublin Core, use (using Edit column → Add column by fetching URLs):
replace("http://sru.swissbib.ch/sru/search/defaultdb?query=+dc.anywhere+%3D+{QUERY}&operation=searchRetrieve&recordSchema=info%3Asru%2Fschema%2F1%2Fdc-v1.1-light&maximumRecords=10&startRecord=0&recordPacking=XML&availableDBs=defaultdb&sortKeys=Submit+query", "{QUERY}", escape(replace(value,/[\.\']/,""),'url'))
To get MARC XML, use
replace("http://sru.swissbib.ch/sru/search/defaultdb?query=+dc.anywhere+%3D+{QUERY}&operation=searchRetrieve&recordSchema=info%3Asrw%2Fschema%2F1%2Fmarcxml-v1.1-light&maximumRecords=10&startRecord=0&recordPacking=XML&availableDBs=defaultdb&sortKeys=Submit+query", "{QUERY}", escape(replace(value,/[\.\']/,""),'url'))
To get MARC JSON, use
replace("http://sru.swissbib.ch/sru/search/defaultdb?query=+dc.anywhere+%3D+{QUERY}&operation=searchRetrieve&recordSchema=info%3Asru%2Fschema%2Fjson&maximumRecords=10&startRecord=0&recordPacking=XML&availableDBs=defaultdb&sortKeys=Submit+query", "{QUERY}", escape(replace(value,/[\.\']/,""),'url'))
Using either of these queries seems to be returning good results. The returned data must be parsed to extract the required fields, for example the following GREL expression extracts the Title from the swissbib data when it is returned as Dublin Core:
if(value.parseHtml().select("numberOfRecords")[0].htmlText().toNumber()>0,value.parseHtml().select("recordData")[0].select("dc|title")[0].htmlText(), null)
All the above operations can be reproduced on an OpenRefine project containing DHS citation data by using this operations JSON expression. See "Replaying operations" in the OpenRefine documentation for more details on how to apply this to an existing project.
Link back to swissbib
Using the above queries, it is possible to receive the swissbib record ID that corresponds to a citation entry. Unfortunately, those record IDs are computed anew every time the swissbib dataset is processed. This ID therefore cannot be used to uniquely identify a record. Instead, it is necessary to use one of the source catalogue ID.
For example, looking at the following returned result (in MARC XML format):
<record> <recordSchema>info:srw/schema/1/marcxml-v1.1</recordSchema> <recordPacking>xml</recordPacking> <recordData> <record xmlns:xs="http://www.w3.org/2001/XMLSchema"> <leader>caa a22 4500</leader> <controlfield tag="001">215650557</controlfield> <controlfield tag="003">CHVBK</controlfield> <controlfield tag="005">20130812154822.0</controlfield> <controlfield tag="008">940629s1994 sz 00 fre d</controlfield> <datafield tag="035" ind1=" " ind2=" "> <subfield code="a">(RERO)1875002</subfield> </datafield> (...) <datafield tag="100" ind1="1" ind2=" "> <subfield code="a">Robert</subfield> <subfield code="D">Olivier</subfield> <subfield code="c">historien</subfield> </datafield> <datafield tag="245" ind1="1" ind2="3"> <subfield code="a">La fabrication de la bière à Lausanne</subfield> <subfield code="b">la brasserie du Vallon</subfield> <subfield code="c">par Olivier Robert</subfield> </datafield> (...) </record> </recordData> <recordPosition>0</recordPosition> </record>
we find that this record has the internal swissbib ID of 215650557 but we know we cannot use it to retrieve this record in the future, since it can change. Instead, we have to use the ID of the source catalogue, in this case RERO, found in the MARC field 035$a:
<datafield tag="035" ind1=" " ind2=" "> <subfield code="a">(RERO)1875002</subfield> </datafield>
A link back to swissbib can be constructed as
https://www.swissbib.ch/Search/Results?lookfor=RERO1875002&type=AllFields
(note that the parentheses around “RERO” have to be removed for the search URL to work).
Further works
This is only the first step of a more general work inside the HDS:
* identify precisely each notice in an article (ID attribute to generate)
* collect references with a separation by language
* clean and refine the collected data
* setup a querying workflow that keeps the ID of the matched target in a reference catalog
* replace each matching occurence in the HDS article by a reference to an external catalog
Team
- Pierre-Marie Aubertel
- Francesco Beretta
- Giovanni Colavizza
- Maud Ehrmann
- Jonas Schneider