This is an old revision of the document!
Big Data Analytics (bibliographical data)
We try to analyse bibliographical data using big data technology (flink, elasticsearch, metafacture).
- more info will follow…
- see also:
here a first sketch of what we're aiming at:
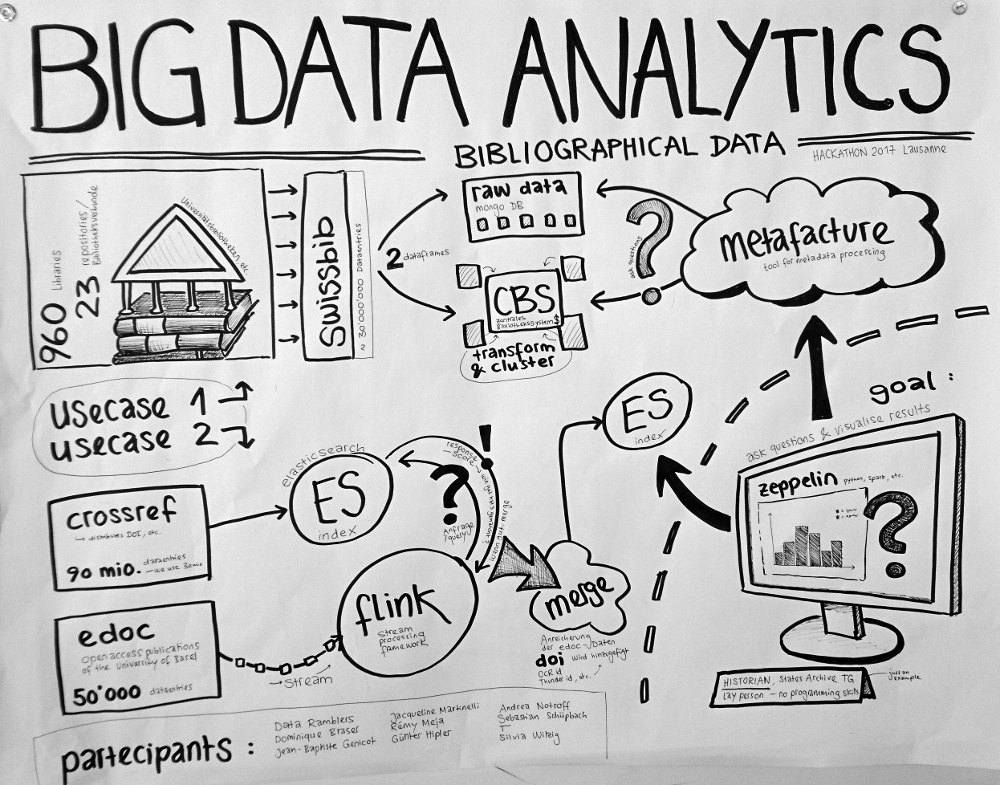
Datasets
We use biographical metadata:
Swissbib bibliographical data https://www.swissbib.ch/
- Catalog of all the Swiss University Libraries, the Swiss Nationallibrary, etc.
- 960 Libraries / 23 repositories (Bibliotheksverbunde)
- ca. 30 Mio records
- MARC21 XML Format
- → raw data stored in Mongo DB
- → transformed and clustered data stored in CBS (central library system)
- Institutional Repository der Universität Basel (Dokumentenserver, Open Access Publications)
- ca. 50'000 records
- JSON File
crossref https://www.crossref.org/
- Digital Object Identifier (DOI) Registration Agency
- ca. 90 Mio records (we only use 30 Mio)
- JSON scraped from API
Usecases
Swissbib
Team
- Data Ramblers https://github.com/dataramblers
- Dominique Blaser
- Jean-Baptiste Genicot
- Günter Hipler
- Jacqueline Martinelli
- Rémy Meja
- Andrea Notroff
- Sebastian Schüpbach
- T
- Silvia Witzig